Article category: Science & Technology, Company News
Descartes Labs Achieves #40 in TOP500 with Cloud-based...
Descartes Labs Achieves #41in TOP500 with Cloud-based Supercomputing Demonstration Powered by AWS,...
Back in 1998, one year after winning his second Gordon Bell prize in high-performance computing, Mike Warren and his colleagues at Los Alamos National Lab assembled the first Linux cluster to appear on the TOP500 list of the world’s fastest supercomputers. Now, leading our tech team 21 years later at Descartes Labs, he’s completed another trend-setting accomplishment by setting a new performance benchmark using virtualized resources in the public cloud, obtaining more petaflops than the fastest computer in the world could in 2010.
Mike’s use of Linux in 1998 was an outlier as it rejected the fragmented and proprietary operating systems that powered each of the other 499 machines on the list. He had grown tired of porting code between IBM, Sun, and a half-dozen flavors of UNIX, so the decoupling of hardware and software that Linux offered was positively embraced. Among other benefits like scalability, interoperability and a worldwide community, Linux allowed Mike and other HPC innovators to change the game by assembling commodity PCs into custom supercomputers of their own.
Today, what was once just a single instance, is now a de facto standard, as every single one of the TOP500 computers on the list run Linux. The adoption of the Linux operating system represented a huge leap in simplifying the design and deployment of HPC applications. It used to be that practitioners would buy a special IBM or Cray system, then it became easy to purchase mail-order PC’s and install Linux, now Amazon and other cloud providers have basically taken the hardware part out of the equation. This latest advancement severely disrupted HPC vendors starting around 2002 as usage split between “tightly-coupled” applications running on dedicated machines and “loosely-coupled” applications running in the public cloud, even though both were using essentially the same hardware underneath.
There are many well-known examples of loosely-coupled applications running successfully on the public cloud with tens or even hundreds of thousands of cores. Applications abound across drug discovery, materials science, particle physics, and the cleaning and calibration of petabytes of satellite imagery that we run here at Descartes Labs. These “massively parallel” applications are amazing in their own right but lack the “interconnect”, or core-to-core low latency network communication that’s needed to power big physics simulations like seismic processing, thermodynamics, cosmology, weather forecasting and more. These highly interconnected applications were previously thought of as only suitable for massive on-premise systems like the Summit supercomputer at Oakridge National Laboratory, or China’s Sunway TaihuLight, the latter being used to simulate the birth of the universe with a technique known as “N-body simulation.”
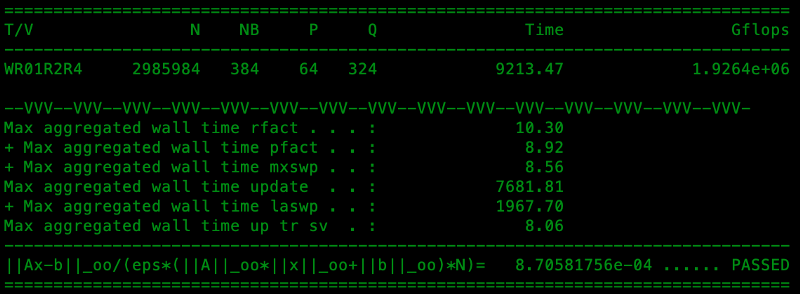
The two supercomputing paths may be starting to merge back together again as our team recently demonstrated on Easter weekend in April 2019. Using publicly available spot resources on AWS, we attained performance of 1.926 petaflops running the standard of HPC achievement, a giant matrix inversion called the Linpack Benchmark. Our engineering team’s goal that day was to use the Linpack Benchmark to see how far the cloud would scale. If it was capable of placing #136 on the TOP500 list then it would be capable of running global-scale customer models for Descartes Labs, including the simulations we developed for Cargill and DARPA.

One of the more interesting aspects of the story is that we didn’t ask Amazon to give our engineers any special dispensation, discount, or custom planning or setup. We wanted to see if we could do this on our own, which if completed successfully, would also be a testament to the self-service model of AWS. Our team merely followed the standard steps to request a “placement group”, or high-network throughput instance block, which is sort of like reserving a mini-Oakridge inside the AWS infrastructure. We were granted access to a group of nodes in the AWS US-East 1 region for approximately $5,000 charged to the company credit card. The potential for democratization of HPC was palpable since the cost to run custom hardware at that speed is probably closer to $20 to $30 million. Not to mention a 6–12 month wait time.
Mike believes this is the first time “virtualized” processors have been used on the TOP500 list, although AWS has been on before with a four times smaller 0.484 petaflop setup that was widely believed to have been run on bare hardware. Our system leveraged unique technical details like a fine-tuned hypervisor between the Descartes Labs code and the virtualized AWS Intel Skylake processors, as well as advanced use of MPI messaging, and Packer, a tool for creating identical machine images that manage the software configuration on each node. All of these taken together may mean the Descartes Labs system is deserving of its own software category on the TOP500 list.
Mike Warren’s vision today is a continuation of the story that started with Linux in the early days. He’s aware of the common refrain that “everyone knows the cloud is useless for tightly coupled HPC.” But he believes that just isn’t true. The cloud can definitely be used. It’s not magic, just a mix of experience, skill, and a mind for innovation. For some reason, others just haven’t really tried it yet. It’s kind of like how no one knew you could use mail order PC’s to roll your own supercomputer, or no one knew you could use Linux instead of dealing with the latest flavor of UNIX shipped on an IBM or Cray.
Back at our headquarters in Santa Fe, our team is constantly tuning the ideal architecture needed to serve our global-scale earth science projects. These include large-scale weather simulations, giant 3D Fourier transforms in seismic modeling, and greenhouse gas mixing dynamics in the atmosphere. We believe that true HPC applications will eventually migrate over to the cloud en masse. The advantages versus traditional supercomputers are hard to ignore. HPC professionals can buy their own machine at a massive cost or rent time on a highly specialized cluster somewhere that uses an old version of Linux from two years ago that needs to be brought up-to-date. But in the cloud, it’s all under your control. There can be seven different versions running different Linux kernels tuned for specific applications and it’s all easy to manage.
In summary, Big machines have historically been used for a very specific purpose, but the cloud is generalizable across purposes. The democratization of HPC is bringing the price point down to something that’s available to business, and we are well positioned to help our customers take advantage of it. We’ve built a Data Refinery that processes location-related data across the world and makes predictions about future states. These predictions are made possible only by scaling up a supercomputer in the cloud that can handle petabyte or exabyte datasets. This scaling enables our customer models to become truly global in their size and scope.
If you have a complex systems problem that you previously thought was too expensive or complicated to model, consider contacting us to learn more. Until then, keep an eye out for our tightly-coupled supercomputer in the cloud on the latest TOP500 list.